
STYCZEŃ 2023| LJK | ~2000 słów
WPROWADZENIE — Odkąd tylko zaczęto zbierać dane, powracało pytanie, co należy zrobić, gdy jakaś obserwacja swoją wartością mocno odstaje od pozostałych – czy jest ona elementem zjawiska, obserwacją, która może się pojawić, ponieważ charakter zjawiska dopuszcza taką możliwość, czy raczej jest błędem w pomiarze, literówką powstałą podczas wpisywania danych do bazy. Weźmy kilka obserwacji: 1,6,2,8,9,100,2,3 – wartość sto od razu rzuca się , ale czy wolno ją po prostu usunąć? Gdyby było pewne, że jest to błąd w zapisie, sprawa rozwiązałaby się sama.
OUTLIERY TO OBSERWACJE ODSTAJĄCE. Out znaczy na zewnątrz, a lier jest od leżenia. Outlier znaczy leżący na zewnątrz. Śmieszne, że u nas w Polsce odstająco się stoi, a w angielskim leży.
WZÓR NA OUTLIERY — Czasami pada pytanie o wzór na outliery. Jedyny wzoropodobny produkt, jaki mi przychodzi do głowy to uwzględniający rozstęp międzykwartylowym, IQR (interquartile range). Wartości, które znajdują się powyżej 1,5·IQR (rozstęp międzykwartylowy) od każdego z kwartyli, to właśnie obserwacje odstające outliery. Widać je szczególnie wyraźnie na wykresie skrzynkowym (boksplocie), gdzie mamy skrzynkę, wąsy i inne dodatkowe elementy.
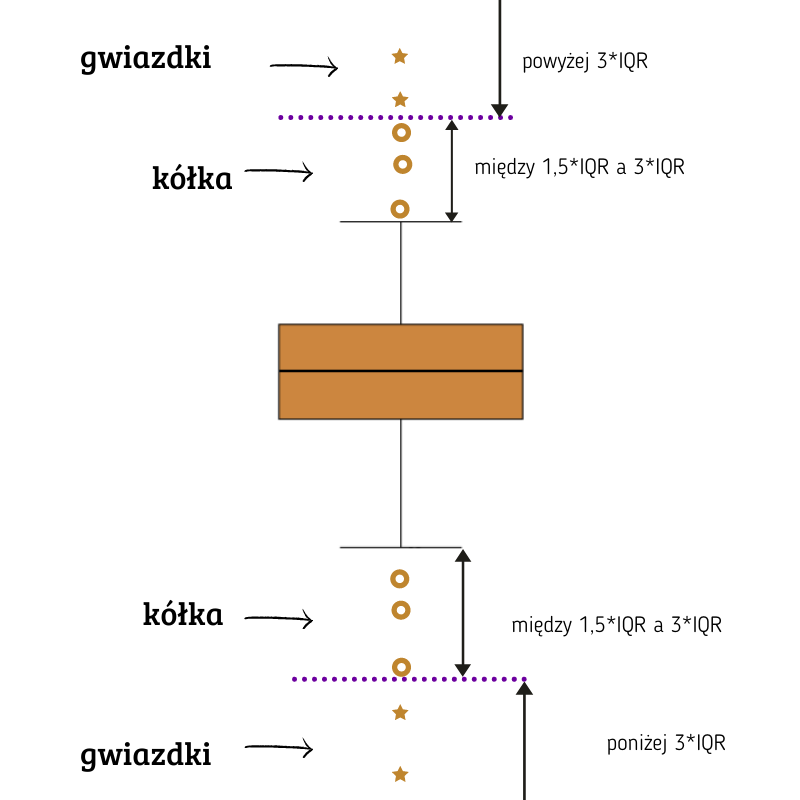
Długość skrzynki wyznacza rozstęp międzykwartylowy (jest to różnica między górny kwartylem Q3 a dolnym kwartylem Q1). Koniec każdego z wąsa znajduje się w odległości 1,5 · IQR odejmowanego raz od dolnego, a raz od górnego kwartyla. Jeśli obserwacja nie wejdzie w zakres między dolnym a górnym wąsem, to uznaje się, że jest obserwacją odstającą.
Programy statystyczne zaznaczają takie obserwacje różnymi kółkami i gwiazdkami. SPSS postępuje w ten sposób, że kółkami zaznaczone są takie obserwacje, które wprawdzie znalazły się poza zasięgiem wąsów, ale mieszczą się w zasięgu dwukrotnej długości wąsa. Gwiazdkami zaznaczone są takie, którymi nie można sięgnąć nawet dwukrotną długością wąsa. Więcej znajdziesz w poście o wykresie skrzynkowym i diagnostyce normalności.
Według tej samej filozofii, na jakiej oparła się ta zasada, przyjmujemy też pewne założenie o rozkładzie cechy. A mianowicie to, że badana cecha ma (teoretycznie) rozkład normalny. Zarówno podstawą tego wzoru, jak i boksplota przyjmuje się rozkład normalny jako rozkład odniesienia. Nie zawsze to założenie da się utrzymać.
OUTLIERY KOJARZĄ SIĘ Z NIETYPOWOŚCIĄ - Ale nietypowość trzeba jakoś zrozumieć, zdefiniować, określić. Można by pomyśleć, że kluczem do zrozumienia nietypowości outlierów jest po prostu sama ich wartość. Przecież najczęściej spotyka się właśnie tak definiowane outliery jako obserwacje, które są różne (odległe) od pozostałych. Ich nietypowość jest mierzona różnicą między ich wartością a na przykład średnią arytmetyczną. Im dalej od średniej, tym bardziej nietypowo. Tymczasem nietypowość bierze się nie z samej wartości, np. 1,72, a z tego, jak często taka wartość może się zdarzyć.
PRZYKŁAD — Ocena 5 z klasówki sama w sobie nie oznacza nic - jest zależna od kontekstu. Raz przecież piątka jest typowa (na przedmiotach łatwiejszych, np. plastyka... chyba), a raz jest nietypowa, jak na przedmiotach ścisłych. Przepraszam w tym miejscu wszystkich nauczycieli fizyki, matematyki i chemii za to, że straszę Waszymi przedmiotami, ale sami wiecie, jak jest. Są to przedmioty, które wymagają więcej wkładu ze strony ucznia (ze strony nauczyciela też), więc siłą rzeczy, częstość piątek jest inna niż na takiej religii.
Aby nieco odejść od przedmiotów w szkole możemy wykorzystać całkiem pospolitą cechę, jaką jest wzrost. Mój wzrost to 171 cm. Czy to obserwacja typowa czy odstająca? Zależnie od tego, na jakim tle ją porównywać.
W przedszkolu większość zerówkowiczów mieści się w przedziale między 110 a 140 centymetrów. Z moim 170 byłabym przedszkolakiem-gigantem, dlatego, że 90 % populacji siedmiolatków osiąga wzrost w przedziale między 110 a 140 centymetrów. Pozostałe 10% jest albo z lewej strony tego przedziału (poniżej 110) albo z prawej strony tego przedziału (powyżej 140). Mój aktualny wzrost znajduje się wiele powyżej górnej granicy. Powiecie, że to niemożliwe, aby taki przedszkolak trafił się? Ogólnie to prawda, to byłby naprawdę rzadki okaz przedszkolaka, ale Gigant z Illinois żył naprawdę i w wieku siedmiu lat miał 178 centymetrów - to nawet więcej ode mnie teraz. Ja i Rober Wadlow (ów Gigant z Illinois) jesteśmy outlierami z prawej strony typowego wzrostu przedszkolaka. Z prawej, bo osiągamy jak na przedszkolaka bardzo wysoki wzrost.
Przenieśmy się teraz do innej grupy. W grupie dorosłych ze swoimi 170 centymetrami jestem typową obserwacją. Zaś w grupie koszykarek byłabym outlierem z lewej strony. Większość koszykarek jest wyższa niż ja. Tak więc, o ile mój wzrost jest jedną z możliwych wartości, jaką można spotkać w gatunku homo sapiens, o tyle to, czy jest obserwacją typową zależy od grupy, od częstości występowania pozostałych wartości. Outlierowość zależy od rozkładu. Zgodnie z powyższym, może się zdarzyć, że cały zbiór składa się z outlierów, bo zamiast zbadać wzrost dorosłych, ktoś trafił do grupy przedszkolaków i jedyną obserwacją, która należy do dorosłych, jest wychowawczyni.
OUTLIERY JEDNO- I WIELOWYMIAROWE — Obserwacja może być outlierem w obrębie jednej lub wielu zmiennych na raz. Weźmy przykład wzrostu przedszkolaków. Ja pośród przedszkolaków różniłabym się wzrostem – byłabym outlierem w zmiennej Wzrost. Ale wzrost to nie jedyna różnica między mną a przedszkolakami - różnię się też wagą, długością rąk, nóg, a mówię tu tylko o cechach antropometrycznych. Jeśli dana obserwacja jest różna od pozostałych pod jednym względem to jest jednowymiarowym outlierem. Jeśli pod więcej niż jednym względem, to jest wielowymiarowym outlierem.
ROZKŁADY SKŁONNE DO POSIADANIA OUTLIERÓW I ROZKŁADY ODPORNE —Są takie cechy, które same z siebie produkują outliery, ze względu na to, że taki mają rozkład. To zależy od kształtu ogonów rozkładu. Jeśli pamiętasz ogólną budowę rozkładów, to wiesz, że można wyróżnić szczyt, ramiona i ogony. Wiesz też, że krzywa ilustrująca rozkład cechy nigdy nie może przekroczyć osi OX (dlatego, że prawdopodobieństwo nie przyjmuje wartości ujemnych).
Jeśli teraz dana cecha ma rozkład, którego ogony szybko dotykają osi OX, wygaszając się po drodze, taka cecha (zmienna) jest ma rozkład odporny na outliery (outlier-resistant). W przeciwnym wypadku rozkład takiej cechy jest rozkładem mającym skłonność do posiadania outlierów (outlier prone). Paradoksalnie to, co zostało powiedziane o rozkładach odpornych na outliery, spełnia rozkład normalny, którego ramiona bardzo szybko zbliżają się do osi OX z jednej i z drugiej strony szczytu.

Z reguły trzech sigma wynika, że rozkład normalny ma szansę równe niecałe 1%, aby pojawiła się obserwacja spoza przedziału +/- trzy odchylenia standardowe od średniej. A im dalej przesunięta od średniej, tym jeszcze mniejsza szansa przytrafiania się. Tyle, że dużą rolę w tym wszystkim gra wielkość próby. Jeśli w dużej próbie, którą podejrzewasz, że wartości pochodzą z rozkładu normalnego, nie pojawiają się żadne obserwacje odstające (kółka, gwiazdki), to znaczy, że nie masz do czynienia z rozkładem normalnym.
Ale 'być odpornym na outliery' a 'nie mieć outlierów' to dwie różne sprawy. Rozkładem, który nie ma szans generować outliery, jest na przykład rozkład jednostajny. Cecha ma rozkład jednostajny, gdy wszystkie jej wartości mają teoretycznie jednakową szansę pojawienia się - to jest jednokrotny rzut monetą, kostką wielościenną. W ten sposób, żadna z wartości nie ma możliwości stać się gigantem ani też karłem.

OBSERWACJE ODSTAJĄCE I WPŁYWOWE — Strach przed outlierami bierze się z tego, że mogą one zaburzać modele statystyczne, na przykład model regresji liniowej. Mogą, ale nie muszą – sprawa jest bardziej złożona. Outlier nie zawsze psuje wszystko, zależy to od tego, czy jednocześnie jest obserwacją wpływową. Obserwacja wpływowa to taka obserwacja, która wywiera duży wpływ na postać modelu statystycznego - na jego współczynniki, w tym: współczynniki regresji. Obserwację wpływową najłatwiej zrozumieć przez to, co się dzieje z modelem po jej usunięciu. A więc, jest to obserwacja, której usunięcie powoduje dużą zmianę współczynników modelu.
Zobaczmy to na rysunku. Wykres przedstawia wykres rozproszenia (rozrzutu, scatterplot) dwóch zmiennych. Każdy pojedynczy punkt to obserwacja i gdy mamy do czynienia z analizą dwóch zmiennych, to słowo obserwacja odnosi się do dwóch wartości – po jednej na każdą zmienną. Mając wykres rozproszenia, chmurę punktów przebijamy linią regresji o określonym wzorze. Gdzie mogą znajdować się obserwacje wpływowe? Cóż, trudno szukać obserwacji wpływowych w środku samej chmury punktów. Usunięcie jednej typowej obserwacji nie spowoduje wielkiej zmiany, bo zawsze wokół są podobnie typowe sąsiadki. Zatem, aby obserwacja byłaby obserwacją wpływową należy szukać jej gdzieś dalej poza chmurą punktów - na rysunku ma kolor fioletowy.

I to, gdzie leży obserwacja odstająca (outlier), ma znaczenie, czy jednocześnie jest obserwacją wpływową. Jeśli obserwacja odstająca leży na linii regresji lub blisko w jej okolicach - jak ta fioletowa obserwacja - wówczas nie ma ona potencjału na bycie obserwacją wpływową. Jej usunięcie niewiele zmieniłoby ułożenie linii regresji. Nadal leżałaby mniej więcej w tym samym miejscu.
Inaczej sytuacja przedstawia się w tym przypadku:

Jeśli obserwacja odstająca znajduje się daleko od linii regresji, wówczas ma tendencje do przyciągania tej linii w swoim kierunku, zaburzając charakter zależności. Ta czerwona linia to linia regresji zaburzona przez obserwację odstającą leżącą w zupełnie innym miejscu niż poprzednio. Może zdarzyć się tak, że nieświadomy obecności wpływowego outliera badacz dojdzie do wniosku, że linia regresji jest prawie równoległa do osi poziomej OX, czyli dany predyktor nie ma znaczenia. Może też uznać, że związek między zmiennymi jest większy niż naprawdę jest (na przykład przy analizie korelacji).
Gdy nie zidentyfikujemy obserwacji wpływowych, może okazać się, że nasz model opiera się w dużej mierze na jednej obserwacji.
DETEKCJA OUTLIERÓW, czyli jak znaleźć obserwacje odstające? — Sposobów na znajdowanie outlierów jest kilka. Dzielą się one na metody wizualne, liczbowe i testy.
- WIZUALNE: boksplot, identyfikuje outliery po tym, że znajdują się poza wąsami wykresu skrzynkowego. Była o tym mowa w tym poście, ale nieco wyżej.
- LICZBOWE: standaryzacja wyników - wyniki surowe przekształcamy do wyników standaryzowanych, zwanych wynikami z. Oznacza to, że od każdej surowej wartości osoby badanej odejmujemy średnią i dzielimy przez odchylenie standardowe. Następnie tak przekształcone wartości porównujemy z wartościami rozkładu normalnego standardowego. Wiemy, że działa dla niego reguła trzech sigma, więc jeśli jakiejś osobie badanej przytrafi się wynik z = 2,74, to wiemy, że jest to wynik, który znalazł się wśród takich, które mają 5% szansę pojawienia się.
- TESTY: test Grubbsa, który bada, czy dany zestaw wyników ma przynajmniej jeden outlier. Minusem tego testu jest to, że porównuje cechę z rozkładem normalnym. Nie jest to jedyny test outlierów, ale w SPSS-ie nie ma żadnych testów.
Najłatwiej jest oczywiście z jednowymiarowymi outlierami - takie od razu widać podczas wstępnych analiz za pomocą narzędzi statystyki opisowej.
CO ZROBIĆ Z OUTLIERAMI? — Wiemy już, że nie można ich wyrzucić tak po prostu. Bycie outlierem nie oznacza od razu bycia pierwszym do usunięcia, ale nie ma jednego dobrego przepisu na postępowanie z nimi, o ile nie jest to wyraźny outlier wynikający z tego, że dana obserwacja nie miała prawa się przytrafić. Jak to się dzieje? Jeśli skala oodpowiedzi rozpina się między 1 (zdecydowanie się nie zgadzam) a 7 (zdecydowanie się zgadzam), to odpowiedź 77 jest zdecydowanie outlierem.
- Po pierwsze - przyjrzeć się danym. Czy dana cecha może przyjść taką wartość? Gdy odpowiedź jest przecząca, wówczas można rozważyć usunięcie wartości w tej komórce.
- Po drugie - sprawdzić, ile wyniosłaby dana statystyka z outlierem, a ile bez outliera? Będziesz wówczas wiedzieć, jak bardzo dana obserwacja ma wpływ na wyniki analiz.
- Po trzecie - stosować metody odporne na outliery, w tym metody nieparametryczne.
STATYSTYKI ODPORNE NA OUTLIERY — Jeśli zdecydujemy się nie wyrzucać obserwacji odstających, nadal mamy pole manewru podczas wykonywania analiz. Istnieją statystyki odporne na outliery. Najprostszym przykładem statystyk opisowych jest moda, a także mediana. Średnia arytmetyczna sama w sobie nie jest odporna na obserwacje odstające, ale możemy przygotować próbę tak, aby wykluczyć wpływ outlierów.
Można to zrobić na dwa sposoby. Po pierwsze można usunąć obserwacje odstające i obliczyć średnią arytmetyczną na pomniejszonym zbiorze obserwacji. Wówczas taka średnia arytmetyczna nazywa się średnią ucinaną (trimmed mean) i outliery nie mają wpływu na jej wartość.
Obok tego, istnieje też sposób bez zmniejszania wielkości próby. Porządkujemy rosnąco obserwacje. Jasną rzeczą jest to, że w takim szeregu outlier będzie albo najmniejszą, albo największą obserwacją. Po uporządkowaniu zastępujemy outliera wartością sąsiadującą z nim najbliżej w tym szeregu. Dopiero na tak zmodyfikowanym zbiorze wartości obliczamy średnią arytmetyczną. Nazywa się ona wówczas średnią winsorowską. Winsorowską – bo pierwszą osobą, która wpadła na ten pomysł, był Charles Winsor (bez d w środku, nie jak zamek Windsor).
Statystyką mierzącą zależność między dwoma zmiennymi i jednocześnie odporną na obserwacje odstające jest współczynnik korelacji rho Spearmana, który jest przecież tym, samym co współczynnik r Pearsona, tyle, że liczonym na rangach obserwacji. Skoro mówimy o współczynniku rho Spearmana, należy też wspomnieć o całej gałęzi statystyki, jaką są metody nieparametryczne. Ale to i tak dopiero wstęp do statystyki odpornej na outliery.
Ignorowanie lub wyrzucanie go może skończyć się źle dla nas. Możemy nasze wnioskowanie oprzeć na części danych, tej części, która mówi złą historię. Znamy to z własnego życia - ile to razy źle odczytaliśmy czyjeś zachowanie i myśleliśmy, że istnieje coś, co nie istniało. Ryzykujemy zawód i rozczarowanie. W Internecie krąży charakterystyczny obrazek wymownie oddający co się dzieje, gdy tworzymy model nie zwracając uwagi na obserwację odstającą.

Brak komentarzy:
Prześlij komentarz