
| Test t-Studenta jest najpopularniejszym testem stosowanym w psychologii ze względu nie tylko na prostotę wykonania w programie statystycznym, ale także na to, że odpowiada najprostszemu schematowi badawczemu: porównaniom między dwoma grupami. |
SUROWA RÓŻNICA MIĘDZY ŚREDNIMI - Mogłoby się wydawać, że porównanie dwóch grup polega na porównaniu średnich arytmetycznych (badanej zmiennej). Wystarczy odjąć jedną średnią od drugiej i w ten sposób uzyskać informację o wielkości różnic międzygrupowych. Tak łatwo jednak nie jest. Przecież w obrębie każdej z grup wyniki są zróżnicowane - osoby w grupach różnią się między sobą. Nie jest tak, że indywidualne wyniki są równe średniej arytmetycznej (zob. rysunek niżej).

Być może to banalne stwierdzenie, ale badaniach empirycznych zmienność wyników jest czymś normalnym i spodziewanym. Nie dość, że występują różnice między całymi grupami (np. kobiety i mężczyźni różnią się pod względem wzrostu), to jeszcze wewnątrz grup osoby różnią między sobą (np. kobiety również różnią się wzrostem, są kobiety mają 162 cm i 198 cm). Zróżnicowanie wyników indywidualnych przejawia się poprzez różne odchylenia standardowe tej samej zmiennej (np. wzrostu) mierzonego oddzielnie dla dwóch grup. Wobec tego odejmowanie tylko i wyłącznie średnich arytmetycznych nie jest miarodajne.
Porównaj dwa poniższe rysunki. Obserwacje z grupy pierwszej są zaznaczone na niebiesko, obserwacje z grupy drugiej zaznaczone są na zielono. Czarną linią ciągłą zaznaczono średnie arytmetyczne, a dwukierunkowa strzałka to różnica między średnimi arytmetycznymi. Pierwszy rysunek pokazuje, że obserwacje nie zachodzą na siebie, ponieważ pomiędzymi nimi jest jeszcze trochę przestrzeni. Grupy są rozdzielone. Żadna osoba z grupy niebieskiej nie uzyskała tak wysokiego wyniku, aby można było ją zaliczyć do grupy zielonej. I w drugą stronę, żadna osoby z grupy zielonej, nie uzyskała wyniku tak niskiego, który sięgnąłby do wyników grupy niebieskiej.

Na kolejnym rysunku dwukierunkowa strzałka jest tej samej długości, symbolizując tę samą wartość różnicy między średnimi. Jednak obserwacje z obu grup zachodzą na siebie. Są osoby z grupy niebieskiej, których wynik sięgnął wyżej niż kilka osób z grupy. Jest jedna osoba z grupy niebieskiej, której wynik jest wyższy niż średnia arytmetyczna grupy zielonej.

Gdyby nie kreski i kolory można byłoby uznać, ze w zasadzie obserwacje nie różnią się pod względem wyników. A więc analizując wyniki osób badanych rozdzielonych do dwóch kategorii, nierozsądnie byłoby pominąć zmienność tych wyników w obrębie każdej z grup. Zarówno test t-Studenta, jak i wielkość efektu uwzględnia i różnicę między średnimi, i rozproszenie.
BADANIA KORELACYJNE CZY EKSPERYMENTALNE? — Test t-Studenta można zastosować do wyników pochodzących z badań zarówno eksperymentalnych, w których osoby badane przydzielasz losowo do jednej z dwóch grup (kontrolnej i eksperymentalnej), quasi-eksperymentalnych, w których wygląda tak, jakby zadziałał przypadek w dobieraniu osób badanych do warunku eksperymentalnego i kontrolnego (np. płeć), oraz korelacyjnych, w których nie manipulujesz żadną zmienną.
NOMENKLATURA: CZYNNIK I ZMIENNA ZALEŻNA — W związku z charakterystycznym schematem badań, z jakim jest związany test t-Studenta, pojawia się specyficzna nomenklatura. Zmienna, która grupuje obserwacje do grup, nazywa się czynnikiem. Zmienna, której średnie arytmetyczne liczymy, nazywa się zmienną zależną. Warto zapamiętać to nazewnictwo, zwłaszcza, że używa go jeden z popularniejszych programów do analizy danych (SPSS).
Będąc jednym z klasycznych testów statystycznych przeprowadzanych w paradygmacie NHST, test t-Studenta posiada następujący schemat: hipoteza zerowa plus dość mgliście sformułowana hipoteza alternatywna, maszynka do mielenia danych zwana statystyką testową, wartości tej statystyki testowej mają rozkład (zwany rozkładem statystyki testowej), na podstawie którego oblicza się typowość uzyskanego wyniku (w postaci p-wartości) i na końcu oblicza się jeszcze wielkość efektu d Cohena. To jest szybki skrót z posta o mechanice klasycznych testów statystycznych zaś odnośnie wnioskowania znajduje się w serii postów.
HIPOTEZA ZEROWA w teście t-Studenta mówi o równości dwóch średnich (badanej cechy) w dwóch populacjach - między dwoma teoretycznymi średnimi.
Teoretyczne średnie można symbolicznie zapisać μ1 to średnia cechy w jednej populacji oraz μ2 to średnia cechy w drugiej populacji. W ten sposób hipoteza zerowa w teście t-Studenta symbolicznie przedstawia się następująco:
H0: μ1 = μ2
OZNACZENIA — μ1 [czyt. mi jeden] to średni poziom cechy w pierwszej podpopulacji, μ2 [czyt. mi dwa] to średni poziom cechy w drugiej podpopulacji.
INTERPRETACJA — Ten symboliczny zapis można rozumieć w następujący sposób: H0: średni poziom cechy jest równy w obu populacjach. Możliwa jest też nieco inaczej brzmiąca interpretacja: dwie próby pochodzą z tego samego rozkładu. Zauważ, że użyte w zapisie są greckie litery μ oznaczające, że chodzi o populację. To powoduje, że ten drugi zapis bywa mylący i sugeruje, że chodzi o porównanie dwóch próbek. Na chłopski rozum, byłby to zbędny zabieg - po co wytaczać całe testowanie hipotez, aby stwierdzić, czy dwie średnie z dwóch prób są sobie równe lub różne? Przecież wystarczy porównać dwie liczby do tego.
CO JEST ISTOTNE STATYSTYCZNIE? RÓŻNICA W GRUPACH ... CZY W POPULACJACH? — Czasem skrótowo mówi się o istotności (statystycznej) średnich w dwóch grup, np. w tekście jest napisane:"analiza pokazała jedną istotnie statystyczną różnicę między kobietami a mężczyznami". Ten sposób formułowania wyników, sprawia, że bardzo łatwo pomyśleć, że szukamy przymiotnika określającego różnicę w średnich arytmetycznych między osobami w grupach.
Podczas weryfikacji hipotez statystycznych to, co nas interesuje to populacja, a nie próba. Ta składająca się z dwóch grup próba służy jako środek do przeniesienia wniosku z próby na populację. Aby zauważyć niezerową różnicę między średnimi arytmetycznymi nie potrzeba żadnej weryfikacji hipotez. Jeśli średnia arytmetyczna n = 10 pomiarów wzrostu w grupie kobiet wynosi 168,2 cm a średnia arytmetyczna n = 10 pomiarów wzrostu w grupie mężczyzn wynosi 178,6 cm, to widzimy, że te średnie różnią się. Różnica między nimi wynosi 10,4 cm - kobiety i mężczyźni w tej dwudziestoosobowej próbie różnią się pod względem średnich wzrostu. Aby przenieść ten wniosek z próby na całą populację kobiet i mężczyzn, wykorzystuje się weryfikację hipotez.
HIPOTEZA ALTERNATYWNA jest w NHST zwykle dość mgliście sformułowana i brzmi: H1: średni poziom cechy w obu podpopulacjach nie jest sobie równy. Symboliczny zapis przedstawia się w ten sposób:
H1: μ1 ≠ μ2
Obecność takiej niewyraźnej hipotezy alternatywne widać jedynie w tym, czy wybieramy test jedno- , czy dwustronny. Od 28. wersji SPSS dostępne są dwie wersje testu t-Studenta (dotychczas była jedna i nie było żadnej filozofii).
Jednostronny test t-Studenta to test, który sugeruje nierówność w hipotezie alternatywnej, czyniąc z nią tzw. kierunkową hipotezę statystyczną.
H1: μ1 < μ2
Kierunkowość wskazuje na konkretny kierunek zależności: uważamy, że średnia w jednej populacji będzie wyższa niż w drugiej populacji. Zamiast: kobiety i mężczyźni różnią się od siebie (bezkierunkowa), to hipoteza brzmi: "średni poziom badanej cechy wśród kobiet jest wyższy niż u mężczyzn".
W miejsce braku równości pojawia się znak nierówności (mniejsze, większe).
Zauważ, że te symbole użyte w hipotezie zerowej i alternatywnej to greckie znaczki. Oznaczają one, że chodzi o równość średnich w populacji, nie zaś w próbie. Kiedy zbierzesz dwie grupy, to najczęściej będą się różnić średnimi arytmetycznymi. Do zauważenia różnicy między dwiema liczbami nie potrzebujesz testów statystycznych – wystarczy je zobaczyć. To, do czego stosujesz testy statystyczne, to przeniesienie wniosków z próby na populację, a więc czy z tego faktu, że różnią się dwie próby, można powiedzieć, że różnią się dwie populacje, z których te próby pochodzą.
FORMAT DANYCH — w podręcznikach zwany założeniami danego testu, a chodzi o to, co nam potrzeba, aby program statystyczny ruszył z obliczeniami. Dane muszą spełniać kilka warunków, które dla wygody i łatwości zapamiętania warto pogrupować w trzy kategorie. Pierwsza kategoria warunków odnosi się do schematu badawczego. Druga określa typ zmiennej (tj. skale Stevensa) a trzecia kategoria ma charakter probabilistyczny – od danych będziemy żądać pewnego kształtu rozkładów. Te warunki są potrzebne, abyśmy mogli zarówno wykonać test t-Studenta, jak również wyciągnąć poprawne wnioski na podstawie otrzymanych cyferek. .
PIERWSZA KATEGORIA: NIEZALEŻNOŚĆ OBSERWACJI – Niezależność obserwacji sprowadza się do ilości pomiarów dokonanych na osobach badanych. Osoby badane możemy badać raz, przydzielając do jednej z dwóch grup, albo dwa razy - już bez podziału na grupy. Jeden i drugi sposób stworzy dwa zestawy wyników. Pierwszy przypadek to przykład niezależnych obserwacji (nie mylić z niezależnością zmiennych). Obserwacja może należeć: albo tylko do grupy kontrolnej, albo tylko do eksperymentalnej. Być albo kobietą, albo mężczyzną. Są to dwa rozłączne warunki: albo A albo B.
Drugi przypadek to przykład zależnych obserwacji. Łatwiej o nich pomyśleć, jak o powtarzanych pomiarach. Badane osoby przechodzą przez badanie dwukrotnie, więc (nieco sztuczną) grupą jest kolejność pomiaru: pierwszy pomiar, drugi pomiar. Na przykład szybkość przyswajania wiedzy przed spożyciem kofeiny i po spożyciu kofeiny.
Obok tego badacz może przebadać jedną grupę badanych i porównać ich średni poziom z innym, teoretycznym poziomem odniesienia. Na przykład: lekarz medycyny może sprawdzić, czy osoby dotknięte schizofrenią mają książkowe ciśnienie krwi 120/80.
WARIANTY TESTU T-STUDENTA: Możliwość wyboru schematu badania (obserwacje niezależne vs. zależne) powoduje, że istniejeą warianty testu t-Studenta:
- dla jednej próby (one-sample t-test) – to taki wariant, w którym jest jedna grupa, której to średni poziom porównujesz do jakiegoś teoretycznego kryterium, np. czy średnie tętno seniorów wynosi 60 uderzeń na minutę.
- dla dwóch prób niezależnych (two sample t-test) – osoby badane są rozdzielone do dwóch grup i każda z nich jest badana tylko jeden raz, np. zbadano poziom uprzedzenia do wybranej mniejszości u osób mieszkających przy zachodniej i wschodniej granicy Polski.
- dla dwóch prób zależnych (paired data) – badani zostali poddani badaniu dwukrotnie, np. zbadano tętno przed i po treningu.
W tym poście omawiamy test t-Studenta dla grup niezależnych.
DRUGA KATEGORIA: TYP POMIARU zmiennych — Mechanizm testu t-Studenta jest tak skonstruowany, aby badać dwie średnie. Chodzi o to, że wzór, który stanowi sedno tego testu, przyjmuje tylko średnie, odchylenia standardowe i liczebności obu próg. Dane powinny być rozdzielone na dwie kategorie, zaś wybrana cecha powinna umożliwiać obliczanie średniej arytmetycznej na swoich wartościach. Wobec tego, jedna zmienna powinna być jakościowa, a druga - ilościowa. Według skal Stevensa: zmienna, która grupuje osoby badane, powinna być nominalna lub porządkowa o dwóch kategoriach. Druga zmienna powinna być zmienna przedziałowa lub ilorazowa.
Test t-Studenta nie obsłuży takich danych, w których obie zmienne są jakościowe. Nie da rady nim badać związków między płcią a ręcznością (raczej chi-kwadrat). Zmienna musi dawać możliwość policzenia średniej na jej wartościach. Co oznacza, że jeśli pamiętasz skale Stevensa, to musi być zmienną mierzoną na skali interwałowej albo na skali ilorazowej. Druga zmienna musi dawać możliwość rozdzielenia osób badanych do grupy.
Przykłady badań, gdzie test t-Studenta jest użyteczny:
- czy poziom inteligencji emocjonalnej różni się między kobietami i mężczyznami?
- czy nasilenie ekstrawersji wśród aktorów i osób wykonujących zawód bibliotekarza?
- czy deprywacja kontroli prowadzi do ruminacji?
- czy aktywizacja wizerunku rodzica ma wpływ na odraczanie gratyfikacji wśród dzieci?
Dwa pierwsze przykłady to schematy quasieksperymentalne, dwa ostatnie – eksperymentalne, w każdym z nich mamy tylko dwie grupy: wyznaczoną przez płeć, przez typ zawodów oraz kontrolną i eksperymentalną.
Test t-Studenta NIE nadaje się do:
- porównań między więcej niż trzema grupami (idź do: ANOVA)
- sprawdzenia zależności między płcią i stopniem upośledzenia (zmienna nominalna + zmienna porządkowa)
- sprawdzenia czy występuje związek między płcią a zaburzeniem np. czy kobiety częściej występuje schizofrenia (zmienna nominalna + zmienna nominalna)
- związek między samooceną a narcyzmem (zmienna przedziałowa+zmienna przedziałowa)
TRZECIA KATEGORIA: WYMAGANIA PROBABILISTYCZNE — testy statystyczne wykorzystują dane w pośredni sposób – przekształcając je do pojedynczej liczby zwanej wartością statystyki testowej. Statystyka testowa ma również rozkład swoich wartości – jedne zdarzają się częściej, a inne rzadziej. Ten rozkład musi być odpowiednim, ponieważ to na jego podstawie wyciągamy poprawne wnioski. A żeby mieć dobry rozkład, to dane, które wchodzą do statystyki testowej, muszą spełniać trzecią kategorię założeń: normalność rozkładu zmiennej zależnej oraz homogeniczność wariancji.
NORMALNOŚĆ ROZKŁADU cechy w obu grupach. Żądamy, aby w jednej i w drugiej grupie, wartości badanej cechy pojawiały się zgodnie z rozkładem normalnym. Chcemy zobaczyć coś takiego:

Żądanie normalności rozkładu badanej cechy to bardzo mocne żądanie – biorąc pod uwagę fakt, że rozkład normalny w badaniach psychologicznych nie jest często spotykany. Trudno oczekiwać, żeby każda badana cecha miała rozkład normalny, bo przecież test t-Studenta jest najpopularniejszym testem. Musi być jakiś sposób na to, że móc go wykonać, nawet jeśli rozkład cechy nie jest normalny. Z pomocą przychodzi Centralne Twierdzenie Graniczne.
Mechanizm testu t-Studenta tak naprawdę potrzebuje normalności rozkładu statystyki testowej, a nie tego, aby sama cecha miała rozkład normalny. Jeśli wiesz, że badana cecha ma w populacji rozkład normalny, to nie ma najmniejszych obaw - statystyka testowa test t-Studenta ma rozkład dokładnie taki powinna mieć, aby analizy były rzetelne. Jeśli ten rozkład cechy nie jest normalny, to dzięki Centralnemu Twierdzeniu Granicznego i przy dostatecznie dużej liczebności próby można postępować tak, jakby statystyka testowa posiadała pożądany rozkład normalny i procedować z analizami. Oczywiście, zawsze pozostaje pytanie, jak duża próba jest duża.
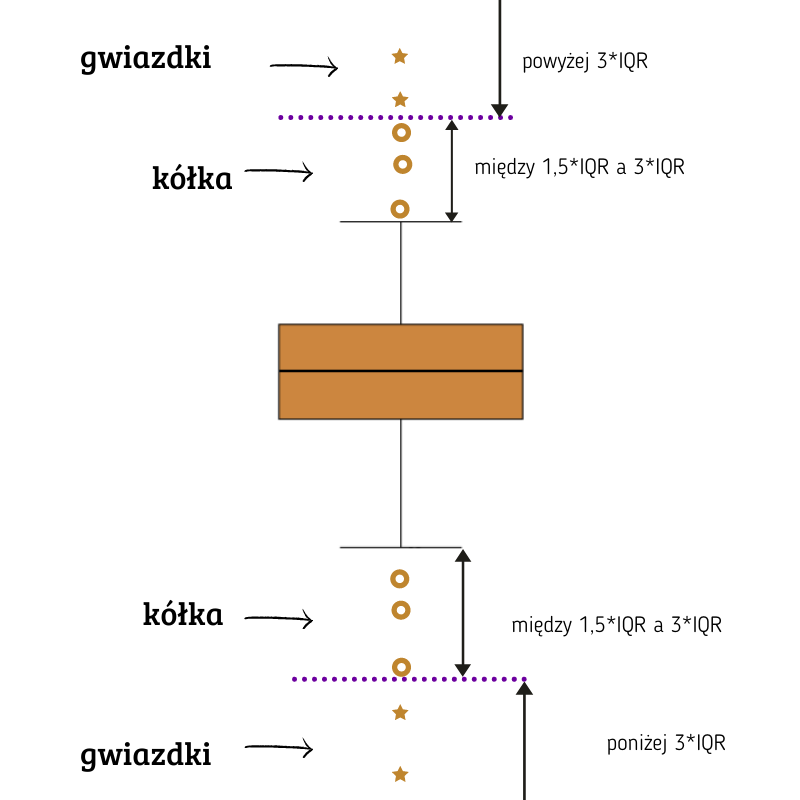
DIAGNOSTYKA NORMALNOŚCI ROZKŁADU - Jest pięć podstawowych charakterystyk potrzebnych do sprawdzenia, czy dany rozkład jest rozkładem normalnym: skośność, kurtoza, boxplot, qqplot, histogram.
Jeśli chcesz dowiedzieć się, jak diagnozować normalność tymi metodami, zajrzyj do posta pt. Diagnostyka normalności: KLIK
HOMOGENICZNOŚĆ (JEDNORODNOŚĆ) WARIANCJI — oznacza jednakowość rozproszeń wyników w obu grupach. Badacz posiada wyniki pomiarów cechy w jednej i w drugiej grupie. Jest zainteresowany ich średnimi – czy może wnioskować, że populacje, z których grupy wywodzą się, są takie same, czy też różne. Podczas dokonywania jakichkolwiek porównań ważne jest to, żeby nie porównywać gruszek z jabłkami, tzn. aby badane grupy różniły się co najwyżej jedną charakterystyką (średnią), nie zaś pozostałymi. Różne rozproszenia (np. odchylenie standardowe) oznaczałoby, że grupy są zbyt różne. Nie dokonuje się porównania między zdolnościami poznawczymi między dorosłymi a przedszkolakami – to zbyt różne etapy w życiu. Z tego powodu oczekujemy jednakowej wariancji w podpopulacjach z jakich wybrano dwie grupy.
I znów – trudno oczekiwać, żeby odchylenie standardowe w jednej i w drugiej grupie było jednakowe. Na przykład odchylenie standardowe badanej cechy w grupie kontrolnej SD = 1,20, zaś w w drugiej – SD = 1,4. Ponieważ mamy do czynienia ze zjawiskami losowymi, których wyniku nie da się z góry przewidzieć, to i nie możemy oczekiwać równości między odchyleniami standardowymi. Musimy się zatem wykazać pewną elastycznością. Innymi słowy, kiedy możemy przejść do porządku dziennego nad niezerową różnicą między odchyleniami standardowymi, a kiedy jest to problem?
Mamy tutaj dwie ścieżki postępowania: albo poprzez oglądanie tych miar rozproszenia, albo poprzez kolejny test istotności statystycznej. SPSS, niestety, promuje pewne zachowania, które nie są do końca są dobre (tzw. testoza – testuj wszystko, co możesz).
SPOSÓB 1 [REGUŁA KCIUKA] — Pierwszy to poprzez podzielenie większej odchylenia standardowego przez mniejsze i sprawdzenie czy wynik tego ilorazu znajduje się poniżej 2. Chodzi o to, że Jeśli odchylenie standardowe
SPOSÓB 2 [TEST STATYSTYCZNY] — Są co najmniej dwa testy homogeniczności wariancji: Levene'a i Bartletta. Oba z nich mają tą samą hipotezę zerową H0: σ1 = σ2 - wariancja zmiennej zależnej w jednej populacji (reprezentowana przez pierwszą zbadaną grupę) jest równa wariancji zmiennej zależnej w drugiej podpulacji (reprezentowanej przez drugą zbadaną grupę). Mocno podkreślam, że próby są tutaj jedynie środkiem do wnioskowania o populacjach, bo siłą rzeczy odchylenia standardowe (czyli pierwiastek z wariancji) uzyskane w badaniu będą różne.
| Problem z testem Levene’a czy Bartletta jest taki sam jak ze wszystkimi testami istotności statystycznej – nie kontrolując liczebności próby, nie za bardzo wiadomo, co ich wynik oznacza. A na dodatek, brakuje im wielkości efektu, zatem tym bardziej trudno ocenić, czy istotny statystycznie wynik testu Levene’a naprawdę pokazuje różne wariancje, czy też nie. Ponadto, takie wielokrotne testowanie wzmacnia testozę wśród badaczy, czyli tendencję do testowania wszystkiego, co się da, byleby nie podjąć własnej decyzji. SPSS jest mistrzem w promowaniu takiego zachowania, ponieważ z tabelek wyświetlanych przez program w outpucie mamy jedynie wynik testu statystycznego i p-wartość. Dzięki temu bardzo trudno jest zapisać wynik testu. Do poprawnego zapisu potrzebujemy jeszcze stopni swobody (degrees of freedom), a nigdzie ich nie ma. |
Po spełnieniu założeń (tych superrestrykcyjnych z normalnością rozkładu badanej cechy w obu grupach) otrzymujemy dane, które w teorii wyglądają mniej więcej tak, jak na poniższym rysunku. Są to dwa rozkłady normalne, które różnią się jedynie przesunięciem na osi poziomej OX - czyli średnią.

Maszynka zwana STATYSTYKĄ TESTOWĄ — Dane wraz z hipotezą testową wkładamy do wzoru na statystykę testową. Ten wzór można opisać krótko jako standaryzowaną różnicę między średnimi, czyli stosunek różnicy między średnimi przez rozproszenie. Problem jaki pozostaje, to jak zmierzyć rozproszenie w obu grupach. Na postać mianownika wpływa równoliczność grup i równość wariancji. Zatem licznik pozostaje takie sam, a mianownik zmienia się w zależności od okoliczności.
Poniższy wzór to jeden ze wzorów na statystykę testową testu t-Studenta: grupy są równoliczne, zaś wariancja jest homogeniczna.

WYNIK STATYSTYKI TESTOWEJ – to pojedyncza liczba. Ten wynik może być mały albo duży. Ujemny lub dodatni. Zauważ, że we wzorze na statystykę testową, w jej liczniku mamy różnicę między średnimi arytmetycznymi. Jeśli średnie są bardzo blisko siebie, to cała wartość statystyki testowej będzie mała.
Ale na obliczeniu wartości statystyki testowej analiza nie kończy się. Ponieważ dane są losowe, to i wyniki statystyki testowej też są losowe. Część z nich jest częstsza, a część z nich jest rzadsza. Ponieważ wartości statystyki testowej mają różne szanse wystąpienia, możemy mówić o rozkładzie statystyki testowej w teście t-Studenta.
ROZKŁAD STATYSTYKI TESTOWEJ – w teście t-Studenta zależy tylko od liczby osób biorących udział w badaniu. Jest to rozkład t-Studenta z pewną liczbą stopni swobody. To na jego podstawie oblicza się p-wartość.

Badacz otrzymuje konkretną wartość statystyki testowej, musi ocenić, czy jest to częsty wynik, gdyby przyjąć, że hipoteza zerowa jest prawdziwa. Zadajemy zatem pytanie, czy otrzymany przez nas wynik jest typowy lub nie, jeśli populacje są sobie równe. Odpowiedź na to pytanie jest w kategoriach prawdopodobieństwa i nazywamy ją albo p-wartością, albo (za SPSS-em) istotnością statystyczną. Więcej na temat p-wartość znajdziesz tutajL KLIK
WIELKOŚĆ EFEKTU - Ponieważ wynik istotny statystycznie może być wynikiem nieistotnym praktycznie, to do oceny siły związku między zmiennymi stosujemy wielkość efektu. Wielkość efektu jest miarą siły zjawiska i w przypadku porównań między dwiema grupami oznacza ona to, jak bardzo średnie badanej cechy różnią się od siebie. Więcej na ten temat znajdziesz w poście o wielkości efektu KLIK
| Warto też powiedzieć, że żeby obejrzeć wielkość efektu w jakimkolwiek badaniu, nie trzeba jednoczęsnie korzystać z testów istotności statystycznej. Test t-Studenta i wielkość efektu to dwie różne rzeczy. |
MIANOWNIK — Skoro różnica między średnimi nie wystarcza, to należy ją podzielić przez jakiś mianownik. Co można włożyć do owego mianownika? Można na przykład zmierzyć wariancję wszystkich wyników bez dzielenia ich na dwie kategorie. Ale takie postępowanie powoduje, że nagle wszystkie wyniki odnosimy do ich ogólnej średniej, a zatem dla jednej i dla drugiej zmieniamy poziom odniesienia, jakim do tej pory była średnia arytmetyczna w danej grupie. Zatem takie postępowanie nie jest dobre.
MIANOWNIK: POŁĄCZONA WARIANCJA [d-COHENA] — W takim razie można spróbować czegoś, co nazywa się wariancją połączoną (pooled variance). Najprościej rzecz ujmując - uśredniamy wariancje i to jest właśnie wielkość efektu d Cohena (d oznacza difference, różnica). Dzięki temu, wyniki odnoszone są do swoich własnych średnich arytmetycznych, a my mamy uchwyconą zmienność wyników w obu grupach.

WIELKOŚĆ EFEKTU d-COHENA — Jest to tzw. standaryzowana różnica między średnimi, gdzie standaryzacja po prostu oznacza podzielenie różnicy między średnimi arytmetycznymi przez rozproszenie wyników bez względu na to, do jakiej grupy należą.
MIANOWNIK: WARIANCJA W GRUPIE KONTROLNEJ [delta Glassa] — technicznie rzecz biorąc, jest to metoda najprostsza. Polega na włożeniu do mianownika zmienności jednej z grupy: tej, która ma być grupą odniesienia. To postępowanie ma sens, gdyby badacza interesowało zestawianie grup i w przypadku badań eksperymentalnych to ma sens. Jedna z nich jest kontrolna, a druga – eksperymentalna, więc siłą rzeczy różnicę między średnimi arytmetycznymi odnosi się do grupy kontrolnej, a dokładniej: względem zmienności wyników w tej grupie. Zatem dla wielkości efektu delta Glassa w mianowniku znajduje się zwykle odchylenie standardowe s jednej z grup.
Wybierając jedną z wielkości efektu, otrzymujemy pojedynczą liczbę (zwaną wartością wielkości efektu d-Cohena/delty Glassa). To może być -0,33 albo 1,25.
ROZMIARÓWKA —
Mała wielkość efektu to te wartości, które zaczynają się od |0.20|.
Umiarkowana wielkość efektu to te wartości, które przekraczają |0.50|.
Duża wielkość efektu to ta powyżej |0.80|.
DODATKOWE INFORMACJE — Jakie wartości mogą przybierać wyniki wzorów na wielkości efektu d Cohena czy delta Glassa? Poniższe własności wynikają wprost z tych wzorów. W liczniku znajduje się różnica między średnimi, zaś w mianowniku pierwiastek. Skoro pierwiastek może być tylko dodatni, to jedynym co ogranicza to różnica w odejmowaniu. A zatem - pełna dowolność.
- Wielkości efektu osiągają wyniki zarówno ujemne, jak i dodatnie..
- W zasadzie nie są niczym ograniczone: wielkość efektu d Cohena czy delta Glassa mogą wynosi -5,23 albo +3,26
DO IT YOURSELF: JAK WYKONAĆ TEST T-STUDENTA W SPSS? — W SPSS-ie klikamy kolejno: Analiza -> Porównywanie średnich. Musimy wybrać zmienną kodującą podział na grupy (np. "Płeć") oraz oczywiście, badaną cechę, czyli kolumnę np. ''MFQ_HARM_AVG''. Tak nazwana jest kolumna oznaczająca wartości zmiennej.

Wybieramy Test t dla prób niezależnych.
Pojawia się okno dialogowe test t dla prób niezależnych.
Musimy teraz wskazać, która zmienna to zmienna zależna, dla której można policzyć średnie w dwóch grupach. Oraz która zmienna to zmienna dwuwartościowa, która grupuje (dlatego grupująca) obserwacje w dwie rozłączne grupy. Można tę zmienną nazwać też czynnikiem.
Kiedy wybierasz zmienną grupującą, to musisz wskazać, jak zakodowano te grupy. U mnie jest tak, że jeśli obserwacją jest kobieta, to ma przypisane 0. A jeśli to mężczyzna, to ma przypisane 1.
Napiszę to na wszelki wypadek, bo niektórzy biorą ten podział osobiście. Żaden podział nie będzie dobry i ktoś się obrazi. Więc... skoro tak... to ja ułatwiam sobie zapamiętywanie pod względem podobieństw anatomicznych :-)

Zmienne wybrane. Naciskamy enter i pojawia się tabelka, w której są dwa testy.

Dlaczego o tym mówimy? Bo wybór odpowiedniego wiersza z tabelki SPSS-owskiej przedstawiającej wyniki testu t-Studenta zależy od wyniku testu Levene'a. I pewnie też ocena na kolokwium czy egzaminie).

W pierwszej i drugiej kolumnie jest statystyka testowa i jej istotność statystyczna. Analizę zaczynamy właśnie od tego testu, dlatego, że w zależności od jego wyniku będziemy interesować się pierwszym lub drugim wierszem w tej tabeli.
P-wartość w teście Levene'a ma wartość dużo niższą od poziomu istotności alfa równego 0.05, stąd pewnie zgodnie z taką szkołą można uznać, że wariancje w grupach nie są równe.
Skoro nie są rówe, to będziemy odczytywać wyniki znajdujące się w drugim wierszu tej tabeli.